
Using an RLM to maintain the OpenClaw repository
Can RLM's handle maintence tasks of huge repositories.

The Problem
OpenClaw is the fastest growing github repository of all time. It has over 200k stars, 400k lines of code and over 4k open pull requests. Agent driven development has led to an explosion of people who can contribute, but it also has resulted in a lot of slop. The creator and maintainer team cannot keep up and current solutions don’t work for a repo of this scale. Today nothing triages these PR’s effectively at the current scale.
Attempt #1 Agent Swarm
My first instinct to solve this problem was to leverage clawdbots to enter a decentralized network of coders and reviewer adversaries. My intuition was that if clawdbots were submitting PR’s they should also be required to participate in reviewing and triaging PR’s from other agents. At a high level the agent github was a network of agents that read from a shared task queue to ensure the agents picked up unique coding or reviewing tasks and the agents didn’t do duplicate work. Internally it was coordination backend with consensus voting, reputation scoring and a clean interface for OpenClaw agents to register and operate autonomously. The results of this were 70 code changes for OpenClaw that greptile gave a 4 or 5 in readiness and most of the CI steps passing.
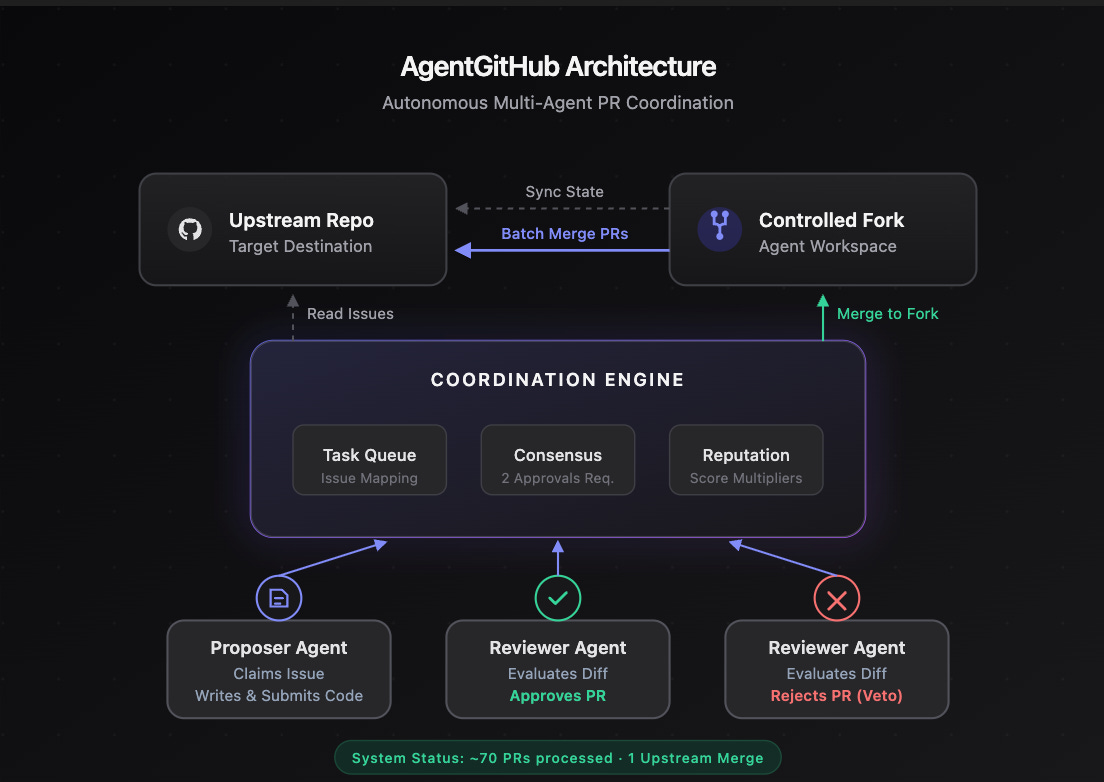
In actually trying to merge some of those 70 changes I saw that the bottleneck for OpenClaw maintenance is that there are thousands of issues and PR’s of varying quality. The agent swarm cost me ~200$ in tokens and only 1 PR ended up merged because of a ping I got from another developer about the fix being useful to them. The decentralized approach is inviting as we can use blockchain principles to get consensus on whether a PR is ready for review. However, the bottleneck for that is getting OpenClaw agents sign up for the network and getting native support in the repository. This kind of solution requires too much setup from the maintaners and its not clear if this would even solve this problem.
Reviewing individual PR’s required additional scaffolding to cluster similiar changes and is expensive to run as each agent processes the full codebase per PR. Ideally the task we give the model includes the full codebase, all the PRs and all of the issues which blows past 1M tokens.
Attempt #2 Recursive Language Models
Recursive Language Models (Zhang, Kraska & Khattab, 2024) solve the long-context problem by putting the data in REPL variables. The model writes code to explore them, using queries to split up the data and delegate reasoning to sub-RLM nodes. The model decides what to look at rather than reading it linearly. This paper showed that Qwen3 8B parameter model approached GPT-5 level performance on long-context tasks while using exponentially fewer tokens. As a result they seem to be a good candidate for triaging and ranking the PR’s to review.
My approach was to take a frontier model like Sonnet 4.6 and Opus 4.6, not the papers fine-tuned RLM-Qwen3, with the RLM paradigm to get the benefits of state of the art coding agents and the context efficiency.
I used a seperate job to pull the latest version of open claw, all of its issues and PR’s (with diffs) and store it locally.
We setup a dashboard and are tuning the prompt + tools based on the quality of the output. The task definition I setup is that this task should output a ranking of PR’s scored on quality, urgency and review readiness.
So far we have tried a few versions with varying results. None of these runs cost > 5$
1. Naïve Version
This version uses a very simple prompt instructing the agent to triage low quality PR’s and rank the PR’s based on quality and urgency. In this run the agent extracted the metadata for each PR and then only used that metadata to provide the scores. In ran very quickly and used <20k tokens of context. The model in this case skipped deep analysis of the code and how the PR connects and tried to hack a reasonable output result.
2. Require Codebase understanding
This iteration updated the prompt to instruct the model to ground its decision in the actual codebase and understand the PR/Issue in context of the code. This resulted in the RLM actually understanding the codebase, but when it came to analyzing the code changes it had almost no differentiation in scoring them. It gave most decent PR’s a quality rating of 9 and it was not effective in triaging PR’s that don’t need to be reviewed. We tuned this approach a few times in order to give strict guidance on what the scores meant, but in general this approach struggled to produce meaningful differentiation between PR’s for ranking.
3. Pipeline with adversarial roles
The next iteration in forcing the model to create this curated list we built a structured pipeline that the RLM was prompted to follow. This was a rigid 4-phase pipeline which explicit instruction on how to understand the codebase, analyse the different PRs, using an adversarial review trying to reject the PR and finally a synthesizer to generate the final output. The rigid pipeline produced results with clearly differentiated scores, but looking deeper we lost most of the benefits of the RLM approach as each phase in the pipeline acted as an independent RLM call. This resulted in the pipeline taking a long time and not being very context efficient across the different phases. The next iteration needed to stay more grounded to the papers approach of treating this task as a single RLM node that can spawn sub-RLM nodes.
4. Simpler prompt with more guidelines
Root RLM prompt went from 800 words to just a few lines.
"Triage all open PRs in this repository and produce evidence-backed scored rankings. Use delegation-first RLM flow:
orchestrate at root, collect evidence in delegated subcalls, then synthesize."This produced results that had a reasonable distribution of scores and when manually inspecting the PR’s suggested to review it seemed reasonable to have that score. Here is a distribution of 74 PR’s analysed.
The 2 PR’s ranked > 9 were critical fixes that were identified by cross-referencing the dependency graph.
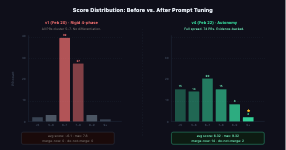
One major issue with this run was that there was no way to look into the agents reasoning as to why it made its decision on the dashboard. For maintainers its not clear why something is a 9.3 vs a 9.1 and more observability into the agents decision making is needed.
5. RLM vs Sub-RLM prompt and tool differences
In the previous versions we use one RLM prompt for the RLM and the sub RLM, but this doesn’t align well with the paper. The paper using different tasks and tools between the root RLM’s prompt and the sub RLM’s prompt. This direction allows us to give the sub RLM more coding specific prompt and tools. This run short circuited because the root node’s prompt did not have the tools to get PR/Issue metadata so it concluded that there were no PR’s to process. However looking deeper, the model shows that it will not hallucinate the scores as shown and if it doesn’t have the PR data it will produce empty triage result.
Cannot produce evidence-backed triage without actual PR
data. Producing empty triage result per honest evidence-only policyLearnings
RLM’s are capable of efficiently analysing a codebase + PR’s to triage them with reasonable quality (manually verified 10 random PR’s and compared my assessment to the agents). It is worth to try to scale out this approach to for all 4k PR’s, but we need to also add automated evals to assign a quality metric to the system. This approach also doesn’t handle the dynamic nature of codebases well, a run that takes 10 minutes to complete could become partially stale on a repo like open claw.
Future direction
The limitation of the current approach is that every run throws aways it work. The RLM processes the entire codebase, reasons over 4k PR’s and builds a structure understanding and discards it. The next run starts from scratch and when a new delta comes in the analysis becomes stale.
The recursive tree the RLM produces is already a structured decomposition of the codebase and its issues. Persisting that tree as a knowledge graph means each sub-node becomes a cached reasoning step. Containing the files analysed, conclusions reached and when it was last updated. When a new delta arrives we retrieve the affected sub-nodes and only re-reasons on those with new context added. The rest of the graph should stay intact.
The root node of any RLM can be viewed as a sub-node in a larger unknown graph, like a proof by induction treats the base case as an instance of the general case. The graph grows and updates itself incrementally instead of being rebuilt everytime. The end goal is a platform that keeps a live, reasoned ranking of PR’s that doesn’t go stale.